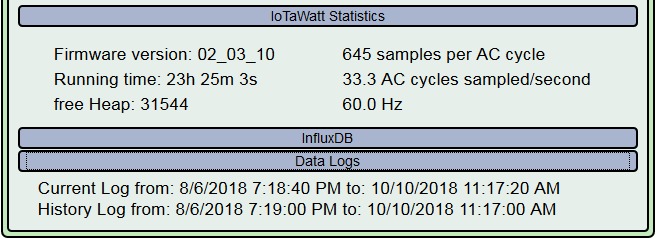
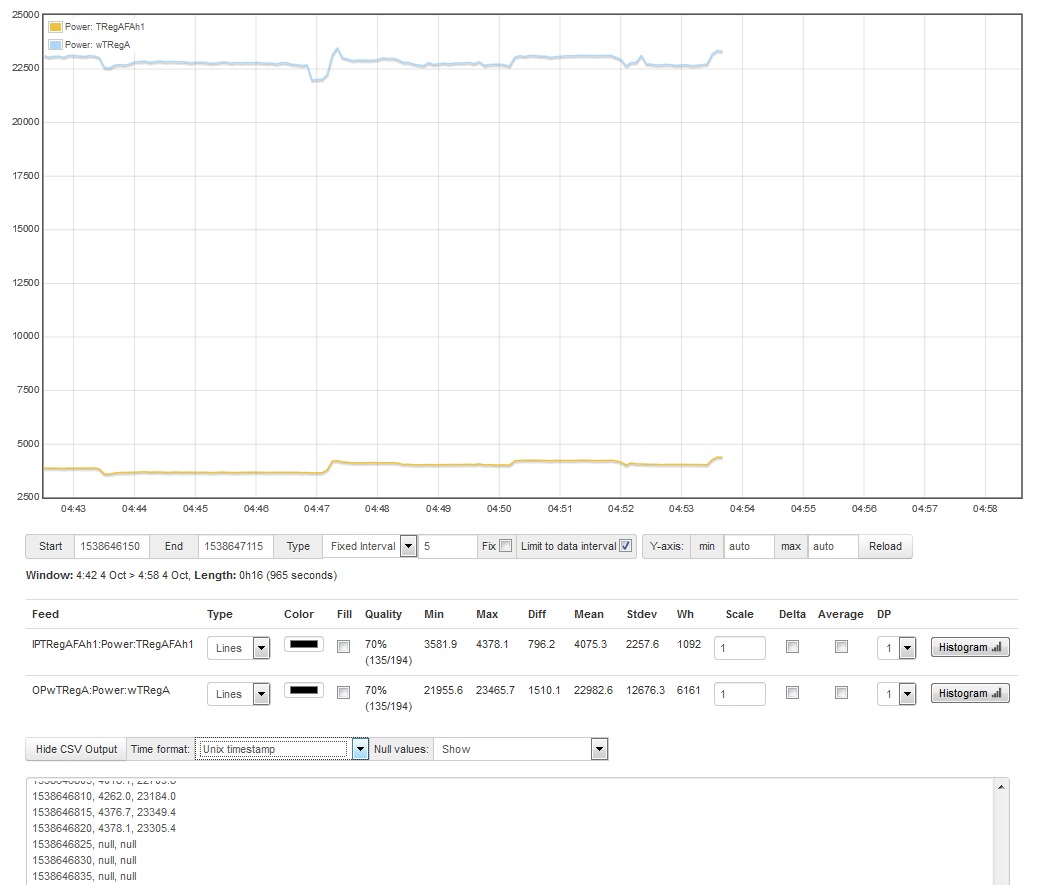
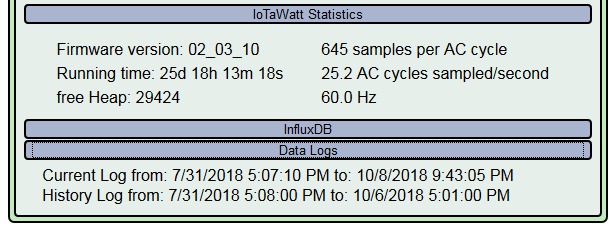
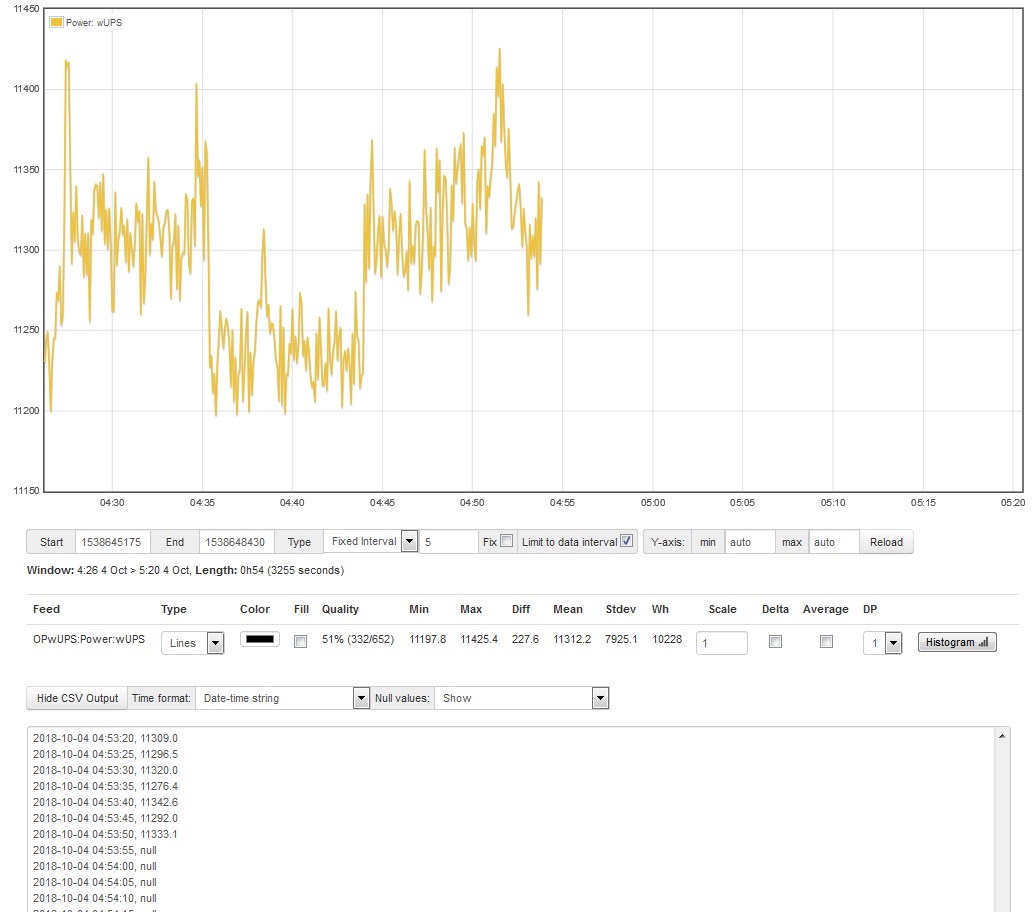
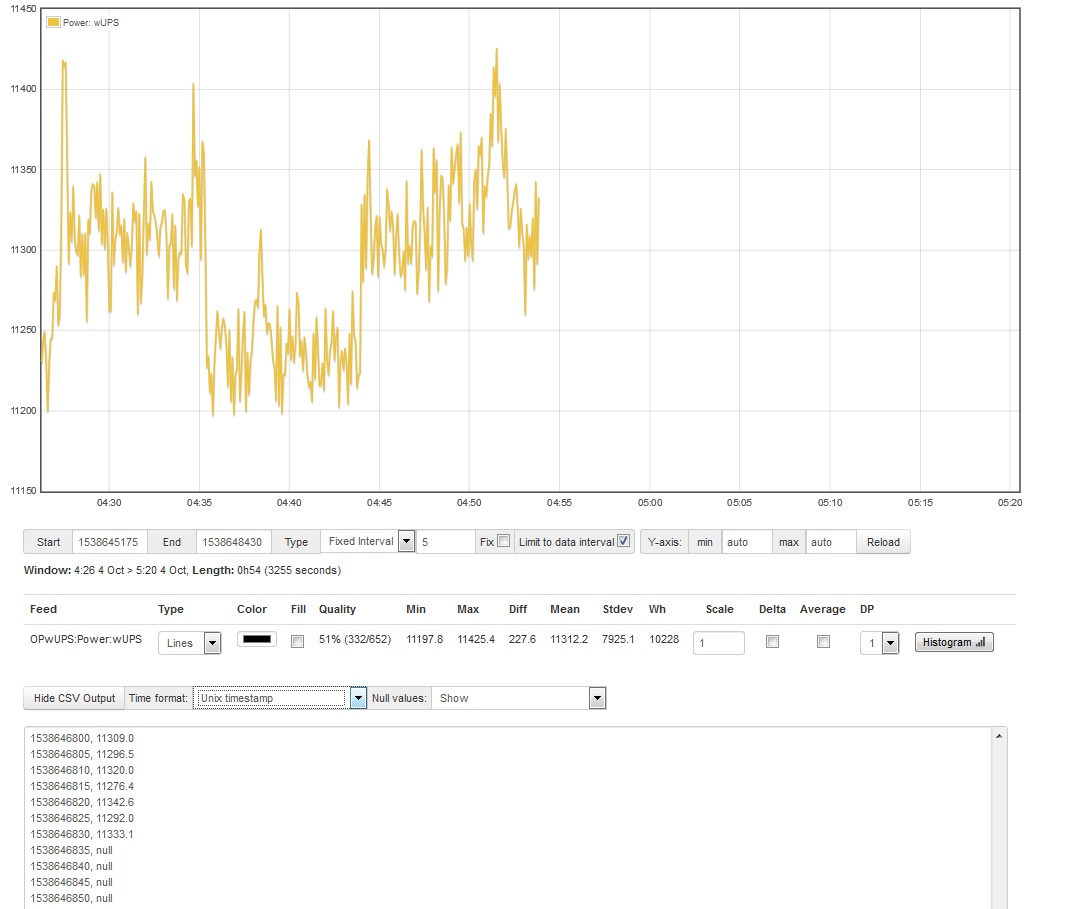
Two of out units apparently stopped monitoring at the about the same time. The units are powered from the same circuit.
The units apparently stopped monitoring but their webpages were still accessible. However the status page was not updating each second as normal. Data was logged as null both for inputs and for computed outputs from the time of the event.
The message log shows a strange time tag in both cases.
10/03/18 10:53:33 timeSync: adjusting RTC by -2
2/07/36 01:28:17 timeSync: adjusting RTC by 547331674
10/04/18 05:53:44 timeSync: adjusting RTC by -547331675
10/06/18 06:54:08 timeSync: adjusting RTC by -2
10/07/18 19:54:25 timeSync: adjusting RTC by -2
I’m including full information for both units. One of the units was already reset and seems to be working fine now. The other unit remains frozen and we’re keeping it as is in case additional information is needed.
That’s a known problem that was fixed in 02_03_13. It has to do with improperly interpreting an error response from the network time servers. Unfortunately it can totally trash your datalog. Apparently your systems are not set for auto-update because 02_03_13 was current for all classes as of Sept 12.
I have problems here with the time servers because some enforce a latency between requests and when you have multiple IoTaWatt they can get several requests from the same IP that looks like a single unit abusing the privilege. So they respond with the “Kiss-o-death” as they call it and all bets are off as to the value of the time fields in that message. It was a beaut to find.
The current general release is 02_03_16 and I would encourage you to set an auto-update class so that you will receive it. The good news is that time services are rock solid now. Units are keeping time to within a few milliseconds and the RTC, which has a resolution of 1 second, is continuously adjusted to stay within that range.
Apparently our units have not lost any data. You think we were spared or it may still happen?
One more thing. You’re right that our units are not set to auto-upgrade. We considered at one point that the issues at the time were minor. I wasn’t aware of this issue, tough. In 02_03_10 there were improvements in the format of reporting to influx. Is the influx implementation in 02_03_16 compatible with 02_03_10? A yes/no would suffice and we’ll tell our DB engineer to take a look at it if changes are needed.