Given the availability of the compatibility APIs. I’d suggest we continue to leverage those and then we can take this at a pace that works for you and this community.
There is no hurry – other than we want to make sure that everyone understands how to get it all working.
2.0 API Overview:
From a /write perspective, that all looks fine. We didn’t make any major changes to line protocol for now. The major changes to the /write API are more around the credential handling. (Now: bucket, organization and token).
The /query side is where there has been significant changes as we have a new functional query language which eliminates many of the limitations/restrictions that were previously in place with InfluxQL. While the syntax is no longer as familiar as SQL, the expressiveness of the language is significantly better including support for variables, result set shaping, nested functions, math across measurements, joins, string interpolation, more native date handling functions…and more.
Here’s the Query API docs.
and an applied example is also documented here.
Using your query above and via curl it might look something like this (replacing everything with and including { }:
curl http://{influxdb_host}:8086/api/v2/query?org={your-org} -XPOST -sS \
-H 'Authorization: Token {YOURAUTHTOKEN}' \
-H 'Accept: application/csv' \
-H 'Content-type: application/vnd.flux' \
-H 'Accept-Encoding: gzip' \
-d 'from(bucket:"{IoTaWATT-bucket}")
|> range(start: {some time -12h or now()-24h or ?? -- a guess at the time is required})
|> filter(fn: (r) => r._measurement == "{measurement}"
|> filter(fn: (r) => r[{tag_key}] = {tag_value} AND.... OR...)
|> last()'
This returns the last field value for each unique group key – based on the filters applied within the measurement provided.
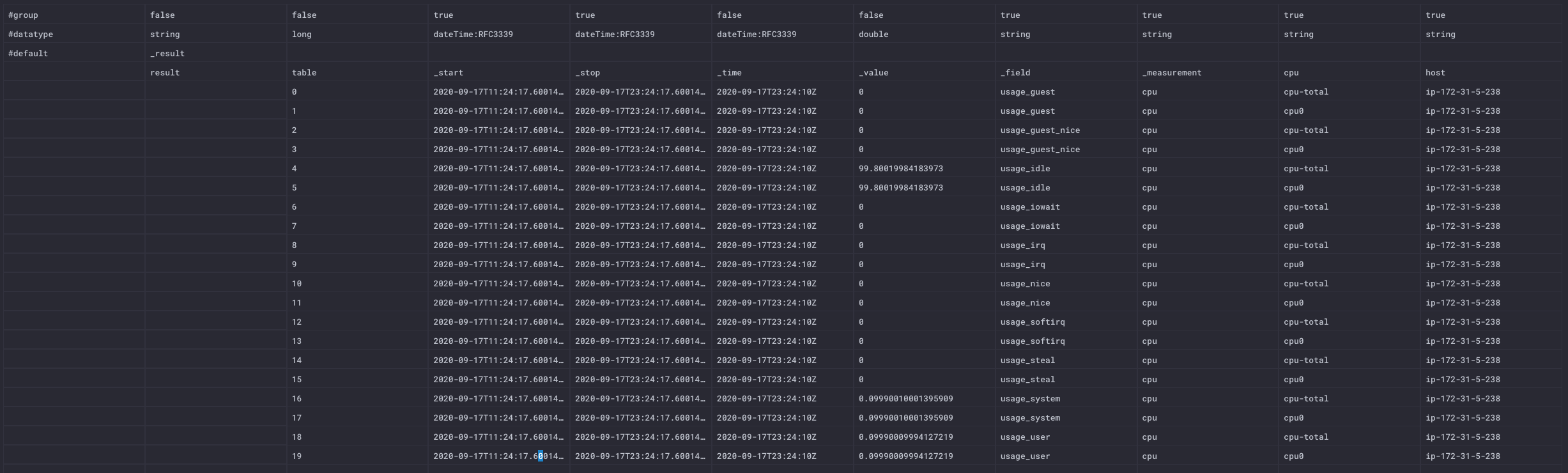
Here is an example
Query:
from(bucket: "my-bucket")
|> range(start: -12h)
|> filter(fn: (r) => r._measurement == "cpu")
|> last()
Results:
You could add more logic to the query if you wanted to do things like stripping off undesired columns, pivot the data to turn the individual fields into a single result set record…and more. The idea is that you can use the query language to shape the data to eliminate complex and extensive parsing.
If you simply wanted the last field for each series key within ALL measurements in a bucket…that can be returned in a single payload with this query:
from(bucket:"{IoTaWATT-bucket}")
|> range(start: {some time -12h or now()-24h or ?? -- a guess at the time is required})
|> last()
The results are grouped into sets based on the annotations required to describe them, but this may be more difficult to parse particularly if you are already setup to loop through the specific measurements.
If you add the pivot to the query after the last():
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
The result set returned is 2 rows of data 1 for each unique series. As I believe you are after the last timestamp of each of the series, this might be the most desirable?
If you only care about the last report, independent of the group key or individual fields, you can modify the group key and simply return the last reported field to the measurement.
|> group(columns: ["_measurement"], mode:"by")
The resulting query looks like this:
from(bucket: "my-bucket")
|> range(start: -12h)
|> filter(fn: (r) => r._measurement == "cpu")
|> group(columns: ["_measurement"], mode:"by")
|> last()
|> pivot(rowKey:["_time"], columnKey: ["_field"], valueColumn: "_value")
Resulting in:
Other changes:
database and retention policies have been collapsed into a single concept: bucket.
Results are returned in an annotated CSV format. The annotations provide additional meta data that can be valuable for understanding and processing the data.
Configuration… I think you can follow the same kind of layout that the Grafana folks took configure a Flux data source.
Again…happy to help.