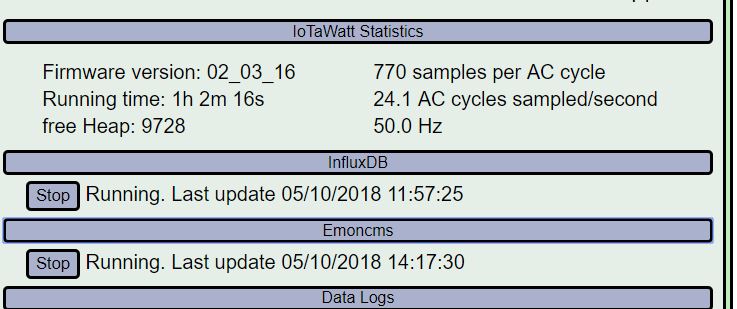
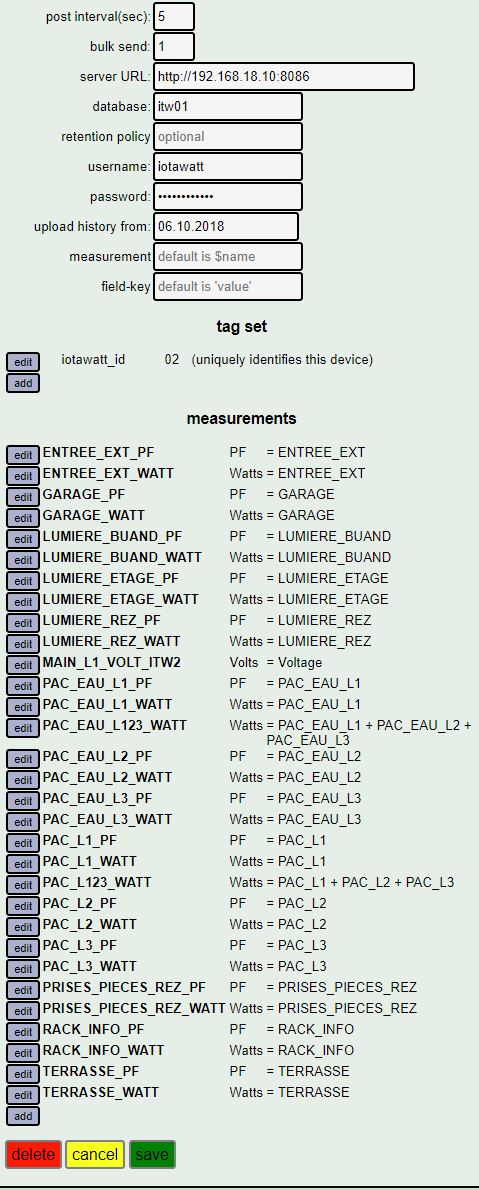
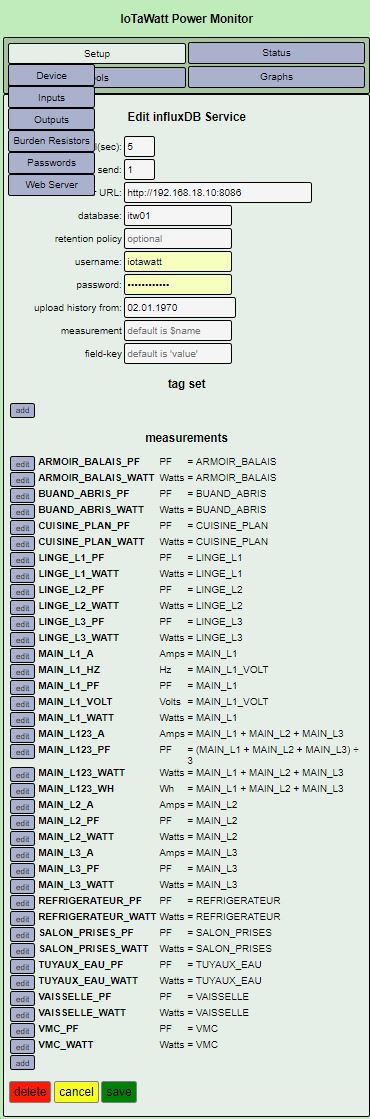
I tried again to start…
suddently it has started… but looks like that there is a heap issue…
It uploads… low heap… restart it continues…
10/05/18 14:18:41 influxDB: started.
10/05/18 14:18:42 EmonService: Start posting at 10/5/18 14:18:40
10/05/18 14:18:43 influxDB: Start posting from 10/5/18 12:25:35
10/05/18 14:19:16 Heap memory has degraded below safe minimum, restarting.
** Restart **
SD initialized.
10/05/18 12:19:17z Real Time Clock is running. Unix time 1538741957
10/05/18 12:19:17z Version 02_03_16
10/05/18 12:19:17z Reset reason: Software/System restart
10/05/18 12:19:17z Trace: 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:4, 18:5, 1:6, 1:3, 1:4, 1:5[21]
10/05/18 12:19:17z ESP8266 ChipID: 6902608
10/05/18 12:19:17z SPIFFS mounted.
10/05/18 14:19:18 Local time zone: 2
10/05/18 14:19:18 device name: pinguIW2, version: 3
10/05/18 14:19:21 Connecting with WiFiManager.
10/05/18 14:19:24 MDNS responder started
10/05/18 14:19:24 You can now connect to http://pinguIW2.local
10/05/18 14:19:24 HTTP server started
10/05/18 14:19:24 timeSync: service started.
10/05/18 14:19:24 statService: started.
10/05/18 14:19:24 WiFi connected. SSID pingu, IP 192.168.18.74, channel 6, RSSI -74db
10/05/18 14:19:24 Updater: service started. Auto-update class is ALPHA
10/05/18 14:19:25 dataLog: service started.
10/05/18 14:19:25 dataLog: Last log entry 10/5/18 14:19:15
10/05/18 14:19:25 historyLog: service started.
10/05/18 14:19:25 historyLog: Last log entry 10/5/18 14:19:00
10/05/18 14:19:27 Updater: Auto-update is current for class ALPHA.
10/05/18 14:19:29 EmonService: started. url:emoncms.org:80,node:pinguIW2,interval:10, unsecure GET
10/05/18 14:19:29 influxDB: started.
10/05/18 14:19:30 EmonService: Start posting at 10/5/18 14:19:10
10/05/18 14:19:30 influxDB: Start posting from 10/5/18 12:48:30
10/05/18 14:19:48 Heap memory has degraded below safe minimum, restarting.
** Restart **
SD initialized.
10/05/18 12:19:49z Real Time Clock is running. Unix time 1538741989
10/05/18 12:19:49z Version 02_03_16
10/05/18 12:19:49z Reset reason: Software/System restart
10/05/18 12:19:49z Trace: 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:2, 18:3, 18:4, 18:5, 1:6, 1:3, 1:4, 1:5[21]
10/05/18 12:19:49z ESP8266 ChipID: 6902608
10/05/18 12:19:49z SPIFFS mounted.
10/05/18 14:19:50 Local time zone: 2
10/05/18 14:19:50 device name: pinguIW2, version: 3
10/05/18 14:19:53 Connecting with WiFiManager.
10/05/18 14:19:58 MDNS responder started
10/05/18 14:19:58 You can now connect to http://pinguIW2.local
10/05/18 14:19:58 HTTP server started
10/05/18 14:19:58 timeSync: service started.
10/05/18 14:19:58 statService: started.
10/05/18 14:19:58 WiFi connected. SSID pingu, IP 192.168.18.74, channel 6, RSSI -74db
10/05/18 14:19:58 Updater: service started. Auto-update class is ALPHA
10/05/18 14:19:58 dataLog: service started.
10/05/18 14:19:58 dataLog: Last log entry 10/5/18 14:19:45
10/05/18 14:19:59 historyLog: service started.
10/05/18 14:19:59 historyLog: Last log entry 10/5/18 14:19:00
10/05/18 14:20:02 Updater: Auto-update is current for class ALPHA.
10/05/18 14:20:03 EmonService: started. url:emoncms.org:80,node:pinguIW2,interval:10, unsecure GET
10/05/18 14:20:03 influxDB: started.
10/05/18 14:20:04 EmonService: Start posting at 10/5/18 14:19:50
10/05/18 14:20:04 influxDB: Start posting from 10/5/18 13:00:10