I had not converted the influxDB driver to use async HTTP in the last release because I no longer had a test system with influx on it. I resolved that this week by loading influx onto a raspberry pi. It was sooooo easy and works great. Very fast.
So now the async HTTP is done and all I have to do is rework the configuration app. With both the Emoncms and influx running async, there’s no reason why the IoTaWatt can’t run both at the same time, and I will work to set that up in a subsequent release, along with some other drivers like MQTT and pvoutput.
But the real story here is influxDB. I’m looking into creating and porting visualization tools to run on influxQL, which should be easy as it’s pretty much like SQL. I think this is going to be a popular option going forward, especially if I can put together a Rpi SDcard with it already installed, along with a server to provision visualization apps.
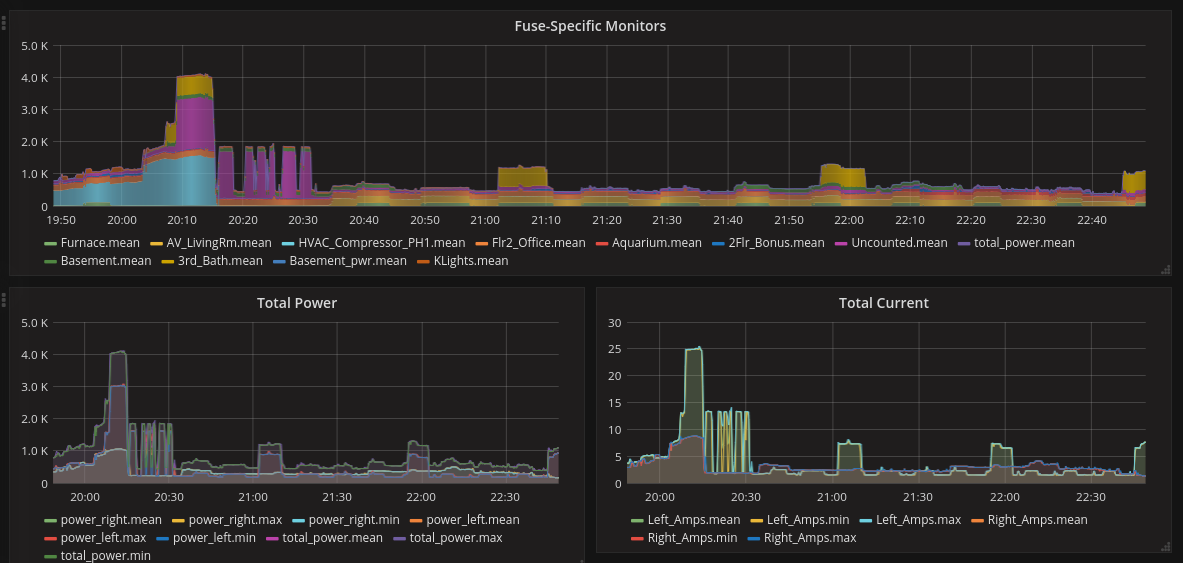
This is working out much better than I had thought. Although the UI isn’t done, I manually edited the config file to start both Emoncms and influxDB services. I hadn’t configured my bench unit (iotademo) to upload to Emoncms for 10 days, so it had a significant backlog to upload. Here’s the unit about halfway through the upload and posting current values to influxDB:
As you can see, heap is still very healthy, and the sample rate is hardly impacted at all. The maximum is 40 AC cycles sampled per second, so running at about 90%.
It looks as if many simultaneous services will work fine, so MQTT, pvoutput, should be little additional load. In the process, I’m making the server upload code more modular, so maybe even eventually get some third party drivers for other protocols.
Bob, I have been using the InfluxDb integration since I bought the iotawatt many months ago. I really appreciate the work going into improving this interface. Influx drives all of my dashboards in grafana which is very great indeed. However, the one thing that I haven’t managed to send to influx is energy consumption (i.e. kWh) which is a shame. Is this possible or any plans to add this to the feed ? Thanks
Hi Pete,
I’m really excited about influxDB and glad to see there are other users out there. I haven’t looked into this in any detail but when I first put influx support in, the guy I was collaborating with said he had figured out how to extract kWh from the power data. He’s not available anymore but that’s worth following up on.
IoTaWatt keeps all of it’s data as cumulative kWh, so it’s possible to do an upload of that, but I hesitate to do that without exploring the aforementioned option. The reason I say that is that I believe influx will accept updates of historical data. Changing some historical power data would need to ripple through a cumulative kWh field.
You can get the kWh directly from IoTaWatt through the graph interface, or directly through the API if I show you how. I’ll be looking into this in a week or so when I get this round of changes done.
Just a heads up about these changes - I’m making a fundamental change to the way IoTaWatt organizes the upload. Previously, each output was a unique measurement with a fieldset value = <value>. and there was no way to associate tag sets.
With the revised implementation, each transaction is a measurement that you name. You can specify any number of tag-sets to be included in the measurement. The individual IoTaWatt outputs (defined with calculator) are the field-sets of the measurement.
The first tag-set, if present, is used to determine the last measurementtime for restart, as in:
select last(field-key) from measurement where tag-key = tag-value
So you may need to make some changes. It will be pretty easy to recreate your influx database (or just add the new measurements to the old one) using the datalog in the IoTaWatt to upload the history. Stay tuned.
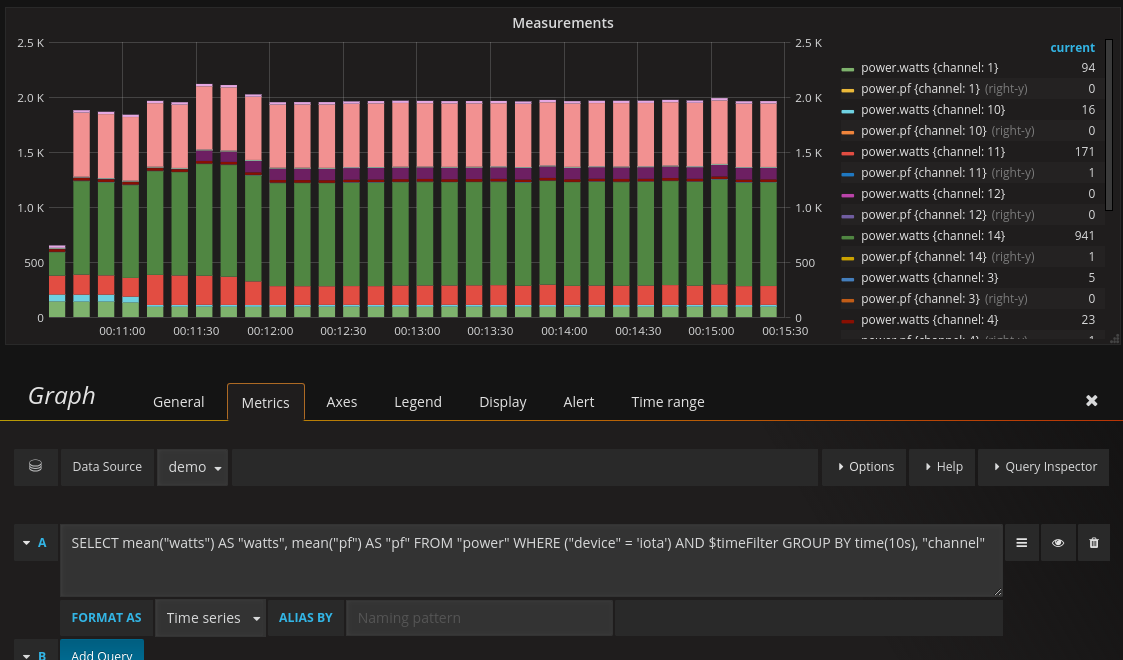
Now that I have influx running well and have uploaded a week of my home history to a database, I’ve had a chance to look into this question. I was able to produce daily kWh for all of my feeds, and you will see that it’s possible to do hourly, monthly whatever.
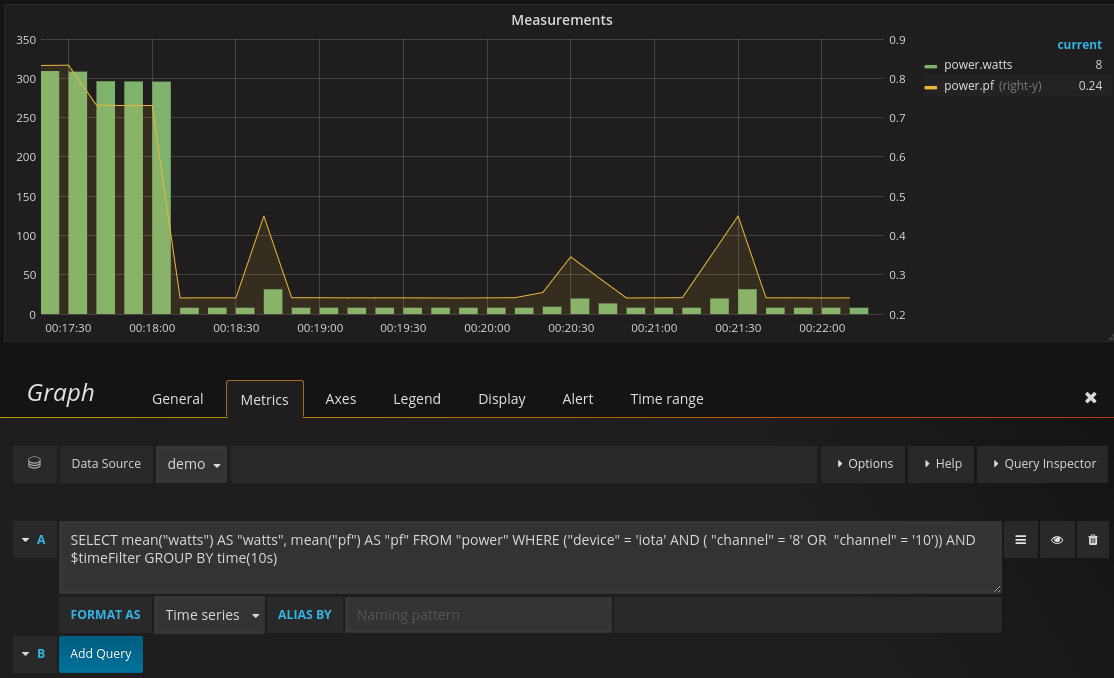
I use the INTEGRAL(field,1h) function, where the field is power in watts. The result is total Wh (watt hours, you need to divide by 1000 for kWh. The values I got match those produced by the IoTaWatt graph function using the cumulative kWh. The query I used was:
SELECT INTEGRAL(*,1h) FROM home WHERE TIME >= now() - 7d GROUP BY time(1d)
This returns the daily Wh for all fields for the last seven days. I could also ask for hourly Wh used by my heat pump for the past 24 hours:
select integral(heat_pump,1h) from home where time >= now() - 24h group by time(1h)
I have a concept for using the calculator units designation to directly export various units like kW, watts, power factor, frequency, etc. When that’s done, you will be able to upload kW and cumulative kW if this INTEGRAL function doesn’t do it for you. It just seems like a waste to upload both the kW and watts when a decent time series database can do the integration.
duh! update - to get kwh instead of wh just up the INTEGRAL unit specification to 1000h
select integral(heat_pump,1000h) from home where time >= now() - 7d group by time(1d)
Hi, new user here – also using influxDB integration to render metrics in grafana.
Figured I’d share this query here: SELECT integral("value") / 1000.0 / 60.0 / 60.0 * $kwh_to_dollar FROM "total_power" WHERE $timeFilter GROUP BY time(12h) fill(null)
I did run into a short issue today – that is related to the topic, but not the response above, sorry for hijacking the thread, but it seems related – that the alpha-channel switched over to your new influx async (it is much faster) but broke my setup. Not a big deal at all, I just downgraded to beta for now, it found the old config and backfilled all the data (awesome!)
Since the influx support is changing (in flux? ) I wanted to suggest a different way to send items to the database. Or at least some level of configuration.
Beta release right now sends items with a new series per measurement/input, this is onerous for lots of measurements (I heavily templated the queries to reduce duplication). I’m not sure the current method of sending data to influx, in the 2_3_2 is much better from a data-management perspective, i’d still have to manually select each measurement, instead of each series. There is some benefit to doing it this way, but all of the measurements are actually “of the same type” and “will all be emitted at the same time,” so I’m not sure its completely necessary.
Might I suggest instead, that each reading from the IoTaWatt be optionally be emitted as a tag instead of a series or measurement.
Ideally, for grafana, I’d like to write one query, that hit all of my real measurements, or “scripted” ones. Filtering by tag is a more typical use-case for Influx.
SELECT integral("watts") / 1000.0 / 60.0 / 60.0 * $kwh_to_dollar FROM "iotawatt" WHERE $timeFilter GROUP BY time(12h),"input" fill(null)
Where input here is defined in the Web Server configuration. It would be trival still to select a specific tag by modifying the query above to:
SELECT integral("watts") / 1000.0 / 60.0 / 60.0 * $kwh_to_dollar FROM "iotawatt" WHERE ("input" = "INPUT_1") AND $timeFilter GROUP BY time(12h),"input" fill(null)
On a separate topic – you’ve got async http working (awesome again!) and 5s is the current minimum measurement time, I’d like to potentially increase that some (at least experiment with it). I was planning on cutting my own build or scraping the status JSON directly, but making that configurable (with an advanced mode or something?) would be great.
So far – I’m super happy with the IWT, the measurements are consistent, the images are signed, the code is open, and its very accurate. Thanks for your work here, happy to be a customer
Oh. Another thing on the status page… power factor is a neat statistic I’d like to track/report to influx.
I’d imagine a query like…
SELECT sum("watts"),mean("power_factor") FROM "iotawatt" WHERE ("input"="input1" or "input"="input2") AND $timeFilter GROUP BY time(30m),"input" fill(null)
… which would be able to sum the left and right power-rails and produce the mean power factor for both. This is difficult in beta today, more possible in alpha using measurements, but super straight forward with tags.
Nothing wrong with measurements, and I understand why you’ve done it both ways (simplicity to configure), just my 2c from other usages of influx and possible queries.
Great Matt. I’m so phyched about influx. The possibilities keep expanding. I have to admit, the query I posted was strictly to demonstrate that kWh can be derived from the power data. I’m still coming up to speed on the infuxQL so you are way ahead of me here.
Sorry about that, hopefully these posts will serve to warn any other influx users out there about the new release.
The new release does change the way items are sent. Previously, each output was a measurement and the value was a field called value. That was awkward. Under the new release, you specify the measurement name for the entire post. Associated with that measurement are the static tags that you specify, and then the individual outputs produced by the scripts (calculator) are fields.
I have broken past support, but seems like the limited population running influx is willing to tolerate that to get new functionality. I don’t want to break it again, and the window is closing on any potential other changes. If you could restate your suggestions as they relate to the new setup, I’ll give it due consideration. Probably lose me in the query descriptions as I don’t really have the full context.
What do you mean by “manually select each measurement”?
I suppose that’s possible, but I’m not following your query example. Can you elaborate how “input” = “INPUT_1” is generated?
BTW, I think integral(“watts”,1000h) is the same as integral(“watts”) / 1000.0 / 60.0 / 60.0 . The integral is seconds so 1000h is 1000 * 60 * 60 seconds.
The 5 second limitation is because the influx (and Emoncms) services are not operating on the real-time data. They are just uploading the datalog, which has 5 second resolution. That’s how these services fill in after an outage. I don’t recommend using the real-time status feed because that’s damped. In any event, unless you only configure a few channels, the device doesn’t sample frequently enough to give meaningful data below 5 seconds. To go the next step like disaggregation, you really need a signal processor.
Power factor (and frequency on voltage channels) is being recorded in the datalog. I’m developing a way to extract that data using the calculator. Right now my thinking is to use different units like - watts, volts, wh, kwh, pf, hz to cause the input to be retrieved in those units.
I can see my example as confusing, let me be more specific. First, I’m specifically referencing “tag_sets” in the influx line protocol format used by the IotaWatt
power input=INPUT_X,device=upstairs watts=<watt measurement> <optional TS>
This example output could be expanded to the following in the example described above:
power input=INPUT_1,device=upstairs,sensor=sct013 watts=<watt measurement> <optional TS>
power input=INPUT_2,device=upstairs,sensor=sct013 watts=<watt measurement> <optional TS>
power input=INPUT_3,device=upstairs,sensor=sct006 watts=<watt measurement> <optional TS>
power input=INPUT_4,device=upstairs,sensor=sct006 watts=<watt measurement> <optional TS>
power input=INPUT_5,device=upstairs,sensor=sct019 watts=<watt measurement> <optional TS>
power input=INPUT_6,device=upstairs,sensor=sct019 watts=<watt measurement> <optional TS>
power input=INPUT_1,device=downstairs,sensor=sct013 watts=<watt measurement> <optional TS>
power input=INPUT_2,device=downstairs,sensor=sct013 watts=<watt measurement> <optional TS>
power input=INPUT_3,device=downstairs,sensor=sct006 watts=<watt measurement> <optional TS>
power input=INPUT_4,device=downstairs,sensor=sct006 watts=<watt measurement> <optional TS>
power input=INPUT_5,device=downstairs,sensor=sct019 watts=<watt measurement> <optional TS>
power input=INPUT_6,device=downstairs,sensor=sct019 watts=<watt measurement> <optional TS>
I suggest the last mainly to allow aggregation across the field types. Which is what I suggested in the final query I posted.
If we assume we also published the PF for each…
power input=INPUT_4,device=downstairs,sensor=sct006 pf=<pf measurement> <optional TS>
In the example spelled out above, I’d change this query to:
SELECT mean("pf"),integral("power")*$conversion FROM "power" WHERE ("input"="INPUT_1" or "input"="INPUT_2") GROUP BY time(30m),"input"
This is all convenience for graphing and aggregating in grafana. I can achieve the same in a polling based python script, that just means re-implementing some of the features (not a big deal! just saw the flux and figured I’d chime in). I will probably skeleton this scraping script out in the next couple of days by parsing the JSON and log. Happy to share that when I do.
Its does seem like a lot of additional traffic (including the tags) but it is nice to be able to aggregate by arbitrary metrics in some cases. I’m not sure what the additional load on the WiFi would be or the additional string manipulation impact.
Anyway, just an idea, based on having done lots of toying in Grafana for other projects.
Matt,
I’m looking at this and I’m still not sure I understand the issue. I need more time to ponder the question, but my thinking right now is that although it may seem to simplify the query, I think it actually may make the retrieval process less efficient. As long as you are querying a specific measurement (power) and filtering by time period, the database engine will need to retrieve as many rows in the table as fit the time period. If those rows contain all of the fields of a particular point, then the values of the various fields can be summed and averaged straightaway. When you specify two field names as tags, I think you are going to do some index work to determine the union of the two tag indices, and arrive at the same set of data points. Then there’s the extra day-to-day overhead in time and storage to maintain all those indices for the tags.
Influx is designed to be indexed by tags, and value compression/retrieval is improved by keeping similar values within the same series.
There is lots of schema design suggestions here.
Distilling my philosophical concerns from the practical “how’s” are mainly:
I’d like to be able to perform any mathematics on any number of inputs and not rely on Iota scripting and be able to utilize influx’s built in capabilities.
This is only achievable in influx by using tags to “select” specific inputs while still reading from the same series.
I’d like to perform my data-mapping within influx (which easily supports renaming fields) instead of within the iota.
I’d like to measure the statistics and deviation across different SCT type sensors and identify when the linearity begins to change (based on temperature it seems some).
There are downsides from Iota’s perspective (additional string work, additional data sent per measurement), but I think its mostly positive to continue exposing the internal functions to influx. The more data that gets exposed, the more operations across series can be done.
Again, I’m just sharing a different data-philosophy. TSDB’s are a bit “different” than databases in how they work and aggregate data. I do agree that its more painful to deal with on the metric emitting side and totally understand if its not worth tackling at the moment.
This is all interesting, but I’m glad you appreciate how much i’ve got on my plate right now. I’ll put those reference on my summer reading list (northern hemisphere) and hopefully over time will be able to balance the utility of what you are saying with the practicality of the impact on IoTaWatt.
Philosophically, my primary concern is keeping the user interface simple and straightforward, so as to make the device useful and unintimidating to as many as possible. Power users like you, if I may put you in that category, will find solutions as you have with the Tick stack.
Hi Matt, I’m also trying to follow your proposal: Do I get it right that you mainly propose to have a possibility to set tags for each channel? This way all power value could have the same field name (for example „power“ and they would only be differentiated with a tag which could for example be “channal_1”.
Saving voltage and frequency in an own measurement seems not so important for the queries you showed.
@overeasy, Just want to see if I have got your original proposal right:
sample period is batched into a single influxdb write transaction
each measurement has the same custom name e.g. “measurement”
each measurement has a tag based on the associated Output (CT/VT) name
each measurement contains fields that correspond to the “units” selected for that Output
So in influxdb line protocol for a particular 5 second period would be something like: measurement,output=hallway_lights power=100,volts=240,kwh=1.23,pf=1.0 14222900257 measurement,output=bedroom_lights power=80,volts=240,kwh=1.01,pf=1.0 14222900257 measurement,output=main_ring power=150,volts=240,kwh=2.75,pf=0.8 14222900257 measurement,output=house_feed power=330,volts=240,kwh=4.99,pf=0.8 14222900257
Which would allow for influxdb tag filtering/aliasing/regex in the query, e.g. select mean("power") where output=/light/ to include all of my light CTs or something like where output!=/house/ to exclude the CT on the main feed. But will repeat the VT information across each of the CT measurements if selected by the user.
Does this simplify the IotaWatt UI to allow you to select multiple “unit” checkboxes for each output e.g. power, kwh, volts… rather than having to create a multitude of outputs to get all of the desired fields. That would be sweet.
Hi Pete,
You’re holding my feet to the fire on this. That’s good. Better to have interested parties critique the approach.
I don’t recall making any proposals. I did change the way it all works, and said I’m open to making more changes while still in ALPHA. What you describe above doesn’t match either the old or new implementations. It’s interesting how you integrated the newer “units” functionality into this, but that wasn’t the intent.
I’m still not convinced of the advantages of sending multiple measurements as you show above.
At the end of the day, at 5 second intervals, the IoTaWatt is going to have posted 17,280 times. Under the new implementation, that will mean 17,280 measurements. No matter how it’s sliced and diced, there will be 17,280 unique timestamps. With the old implementation, that became 17,280 x <#fields> points, and created 17,280 new hashes in <#fields> indices.
What you describe above creates 17,280 x 4 = 69,120 points, and adds 69,120 new hashes to the output tag index.
The new implementation creates 17,280 data points, and adds 17,280 new hashes to <#tags> indices.
All queries, whether implicitly or explicitly, reference the timestamp. They retrieve all of the points in the union of that time domain and any other criteria in the where clause. So in the query:
for the day described, would process the output tag index for the time domain and yield references to 34,560 data points. Those data points would be retrieved and the mean of the power field computed.
In the flat scheme of the new implementation, the query might be:
select mean(/light/) from measurement where <time-clause>
With this query, only the basic flat 17,280 data points are retrieved, and the mean of all of the fields matching the regex is computed. Same can be done for intergal(/regex/,1000h) to get aggregate kwh for the group matching the regex.
I think this is more efficient on a variety of levels, and actually seems like a simpler more efficient query in that multiple fields or regex grouped fields can be processed in a single query, fetching the basic data points only once.
Backing away from the household example, the driving force behind this revamping of influxDB support is the growing interest in using IoTaWatt in multi-site environments. There is growing interest from the property management sector as well as energy management. By exploding the number of points from a single 5sec IoTaWatt measurement into many points, the indices and overhead of the extra labels, tags, timestamps, etc becomes a concerning issue. Retrieving a day or even a month worth of points for a single installation is fairly trivial, and processing as a flat file isn’t going to amount to a lot of work for influx. When a database grows to several IoTaWatt at 100 locations, those extra tag indices would become a real bottleneck, both as the thousands of points are posted every 5 seconds, and when trying to retrieve useful cross-location comparative data. The intent of the tag fields is to allow organizing those various IoTaWatt data into regions, buildings, owners, even countries, and to allow differentiating input from IoTaWatt from other souces contributing the same measurements to the database.
Take a fresh look at what I’m suggesting with using regex on the fields of a flat file and see if it isn’t workable.
I attempted to upgrade to ALPHA again today; but I’m back at BETA for now. Influx porting turned out more complicated than I expected to upgrade (also ran into backfill issues, not 100% sure what those are yet. If I figured that out I’ll make a new thread but it may have been related to all my influx tinkering)
I have another couple of comments regarding Influx usage. The regex field based selection you advocate seems to mostly work. The logging of each “unit” is also great.
This pattern, is however, pretty painful to follow for entering in via the UI (I ended up writing a script to generate the JSON) and its even worse for graphing within Grafana.
While I can write a query such as select mean(/Left_Mains/) from measurement where device='iotawatt' that just seems… strangely formed.
Why is “measurement” there? Is this because of the need to support multiple IotaWatt devices (I would expect the “static” tagging to enable that, not the static measurement).
select mean(watt) from Right_Main where device='iotawatt' seems much more “clear” to me. Perhaps the unit can inform what the field will be? And there would be no need for me to duplicate the “output” field for every measurement I was interested in. Unfortunately this construction does make it /impossible/ to actually do math across measurements; Influx’s continuous queries would be needed here.
Inverting this… select mean(Right_Main) from watt where device='iotawatt' is almost better, but unfortunately you could only combine like units since influx doesn’t permit math across measurements.
Rehashing previous discussion in a new form, I’ll advocate a more influx-idiomatic format: select mean(watt) from iotawatt where device='iotawatt' and output='Right_Main'
or select mean(watt) from iotawatt_device1 where output='Right_Main'
Each of these allow arbitrary combinations and segmentation based on requirements.
Hi Matt,
First the backfill issue. When the influx service starts up, it queries the database for the last entry of the specified measurement with the first specified tag. If there are no tags, it looks for the last entry. Uploading starts with the next time interval after that. If the measurement doesn’t exist, it will start uploading from a week ago, thus providing a week’s worth of data right away.
The one week window was arbitrary. I could have gone with the oldest entry in your current log, or the present time, or a month ago. Now that it’s all working, I’ll try to provide a way to specify the starting time for upload for a new measurement.
There is a workaround. If you are making a new measurement, say “homepower” in a database called “iotawatt” with no tags, and you will want to start uploading from Jan 1, 2018. Before starting an iotawatt service for that measurement, you can seed your database with a starting entry using the following CLI command:
insert homepower first=0 1514764800000000
To get the time string I used one of the online unix time converters to get the unix millisecond time for 1/1/2018 and added three zeroes to convert to nanoseconds. There may be a way to specify the date directly but I couldn’t do it easily. In any event, that will seed your database for that measurement and the IoTaWatt will start uploading from there. If you are using tags, add the first tag to the insert using the standard line protocol.
As I look at what you are doing, the scenario is three outputs for each input = potentially 14x3 = 42 outputs. That’s a lot. No matter how you slice it, your gonna do a lot of typing. I might caution you as well that will generate some very large transactions to influxDB and you are doing it every 5 seconds. This is, after all, an IoT device and there are limits to the size and throughput available. I think it will handle it, but bulk uploading after a communication lapse for instance could take a really long time and dim the lights for quite awhile.
but the primary mission of IoTaWatt is to be able to easily configure and produce accurate basic usage data. To the extent that you can do what you want to do, have at it, but complicating the user interface to facilitate that level of detail is problematic. That said, I can see now that the underlying Json configuration might be restructured to allow producing multiple measurements and tags that are derived from input fields as you would like. With something like that, the door would be open to a separate application to edit a more complex payload specification - to the extent that heap and HTTP bandwidth will run it.
That is strange. You are using iotawatt for the measurement and also as a key field. Unless you have multiple iotawatt that you want to be able to differentiate, the key would seem to be superfluous.
I’ll refer you to the Schema design discussion from influx. While we don’t know exactly how it works under the hood, there are specific recommendations that influence my thinking:
Store data in fields if you plan to use them with an InfluxQL function
So that says to me that mean and sum and integral work best with data values in fields. I suspect the filed data is stored in time weighted form (so for instance watts is really Wh or maybe Wnanoseconds) That makes the integral and mean functions possible without processing all of the points within a grouping.
Store data in fields if you need them to be something other than a string - tag values are always interpreted as strings
Again, these watts and volts are numbers, storing them as strings is inefficient.
Don’t have too many series
Tags containing highly variable information like UUIDs, hashes, and random strings will lead to a large number of series in the database, known colloquially as high series cardinality. High series cardinality is a primary driver of high memory usage for many database workloads.
I think in this context watts (to several decimal places) would be considered highly variable. Do you really need to query all of the measurements in which the Left_Main is 1246.34 watts?
Thanks for all this feedback. Even in presenting these counterpoints, I have had to go back and rethink much of this and it helps a lot. Working with grafana now, I’m exploring some interesting features with variables that I think will make it possible to build an interactive panel where you can select fields and tags and possibly units (watts or Wh) as well as time period.
 ) I wanted to suggest a different way to send items to the database. Or at least some level of configuration.
) I wanted to suggest a different way to send items to the database. Or at least some level of configuration.