I’ve tried to look at the code (without actually trying to run it), and also read this:
https://community.iotawatt.com/t/influx-resend-all-historical-data/1002
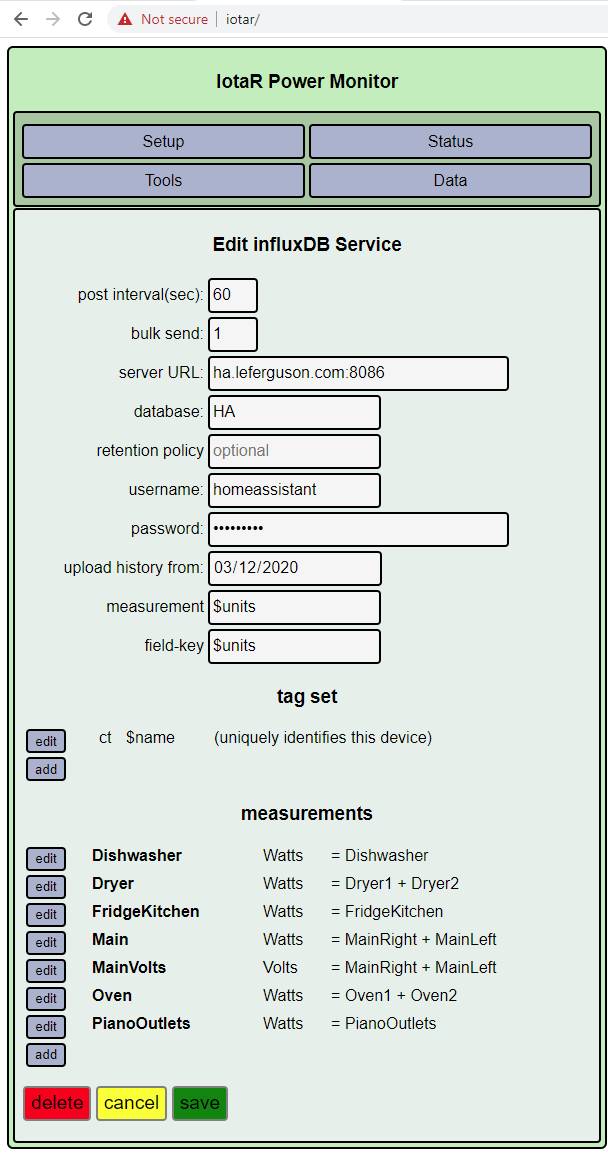
I am using the same measurement name for all data (so I can do math across it inside InfluxDB), with different tags for the ct (really output) name ($name).
Can you confirm my understanding (or correct it): If I add a new InfluxDB output (under the “measurements” section), because the measurement and field name (watts) remain the same, it does not try to send any old data. I.e. when it queries for the last data, it does not query distinguished by tag.
So if I add a new output (which for me becomes a new tag value) it will start sending, but not send any retroactive data. Right?
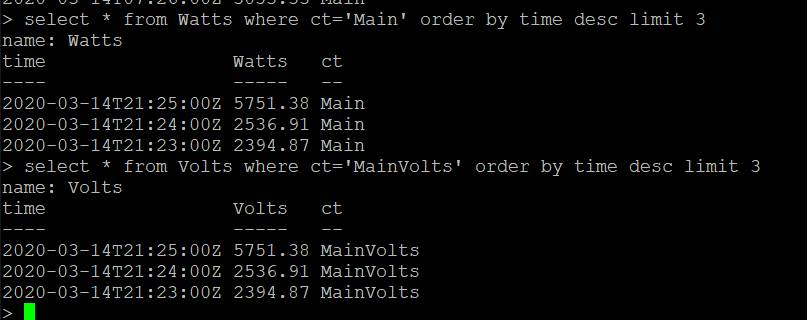
So this is where I am getting concerned. Because I am using the same measurement name for both Iotawatt’s, might I get a race condition where “left” believes it has already sent because its query to the database finds data already present? Or not even a race condition, if one Iotawatt is offline for a bit for some reason (but collecting data), when it comes back it will query and not see the gap, if the other Iotawatt has been sending.
To make this work right I either have to use a distinct Measurement (specifically the thing under “upload history from”), or a distinct field-key?
If I use distinct measurement, Influxdb simply will not do math between measurements, so for example I cannot add up info between the two Iotawatts.
So the only way I can retain safety for catch-up transmissions is to use a different field key per Iotawatt, if I want to retain the ability to do arithmetic?
Or am I missing something?
PS. I am somewhat getting tangled up in the terminology, the section labeled “measurements” and the single entry textbox labeled “measurement” are two different things. I think you are using the latter in the “last” query, and the former become $name wherever you use that.