I’m wondering if there might be anyone here that is good in Grafana? Or if there is a better way to get the information from IoTaWatt
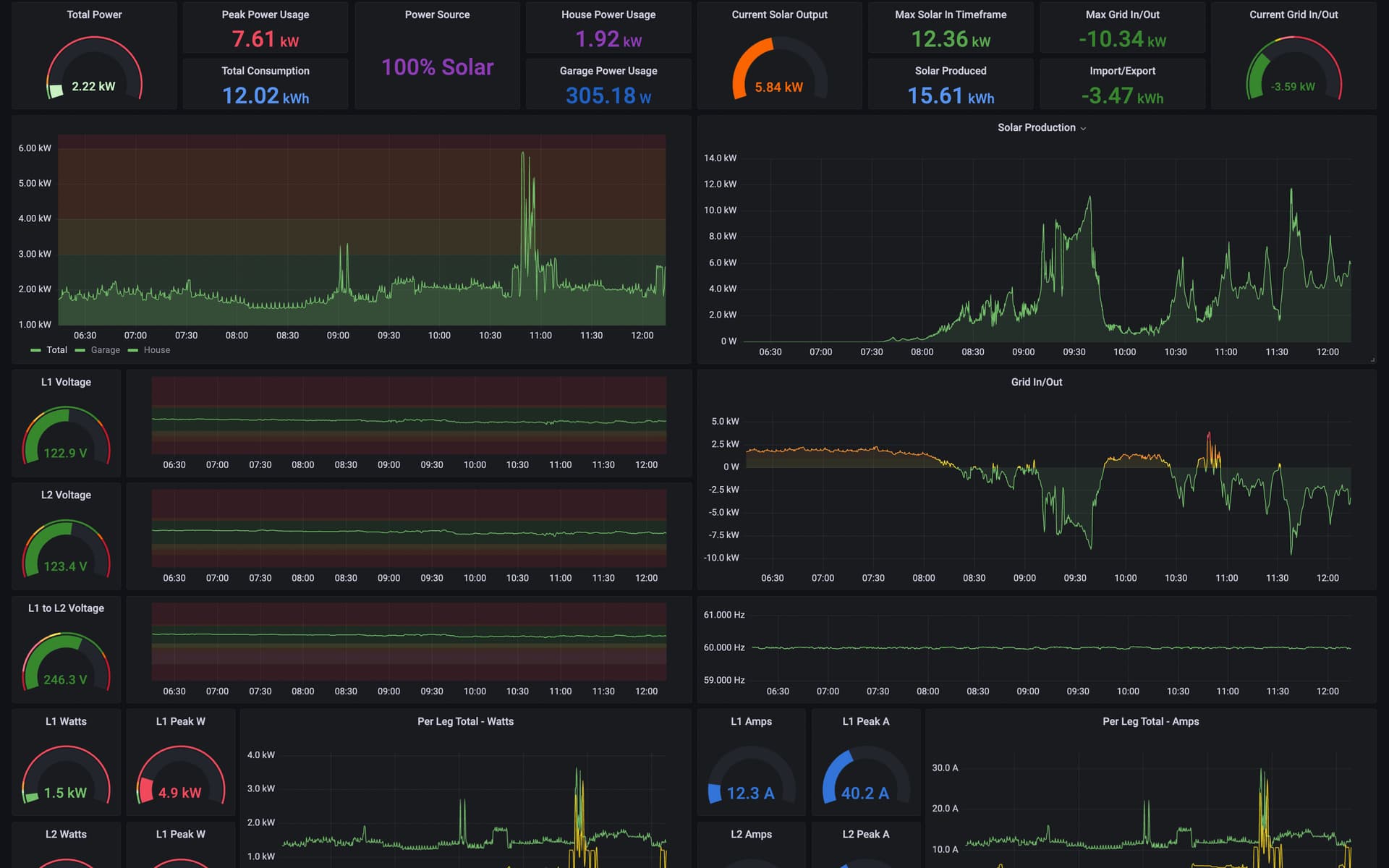
Here is my dashboard. You can see at the top there is a tile that says “100% Solar”. This tile should Go between “100% Solar”, “Grid + Solar”, “Grid Only”, “Portable Generator” and “Standby Generator”
I figured I could use Value Mappings to do it, but I’m not sure how to get it from multiple sources of information.
I have CT’s on my Solar Disconnect (Solar), The Main Lugs AFTER the Solar and BEFORE my panel (Main), On my Portable Generator Inlet (Portable), and on my Standby Generator (Generac). I have a calculation for Main - Solar, which gives me the Grid Import/Export
IF “Main” is a negative value, then display “100% Solar” and be Green in Color
IF “Main” is a Positive Value and “Solar” is over 50w, show “Grid + Solar” and be Yellow In Color
IF “Main” is a Positive Value and “Solar” is less than 50w, show “Grid Only” and be Red in Color
IF “Main” is under 50w and “Portable” is over 50w, show “Portable Generator” and be Purple In Color
IF “Main” is under 50w and “Generac” is over 50w, show “Standby Generator” and be Orange In Color
Does this sound possible?
Of course if I figure it out myself, I’ll post back here with the details
Can’t help on the question (still learning influx/grafana) but thank you for posting your dashboard. Much nicer than my very basic one - it’s given me some ideas.
It is a shame there isn’t a centre zero gauge in grafana (ideal for solar/grid) - have you got around it on your ‘current grid in/Out’ by using colours?
Thanks, if you would like the code for my dashboard or any specific information just let me know, happy to share
Yeah, I agree. I looked for a center zero and I couldn’t figure it out. I think there might be a way using thresholds, but I couldn’t get it to work right. Yeah, I have colors. Green is for exporting and red is for importing
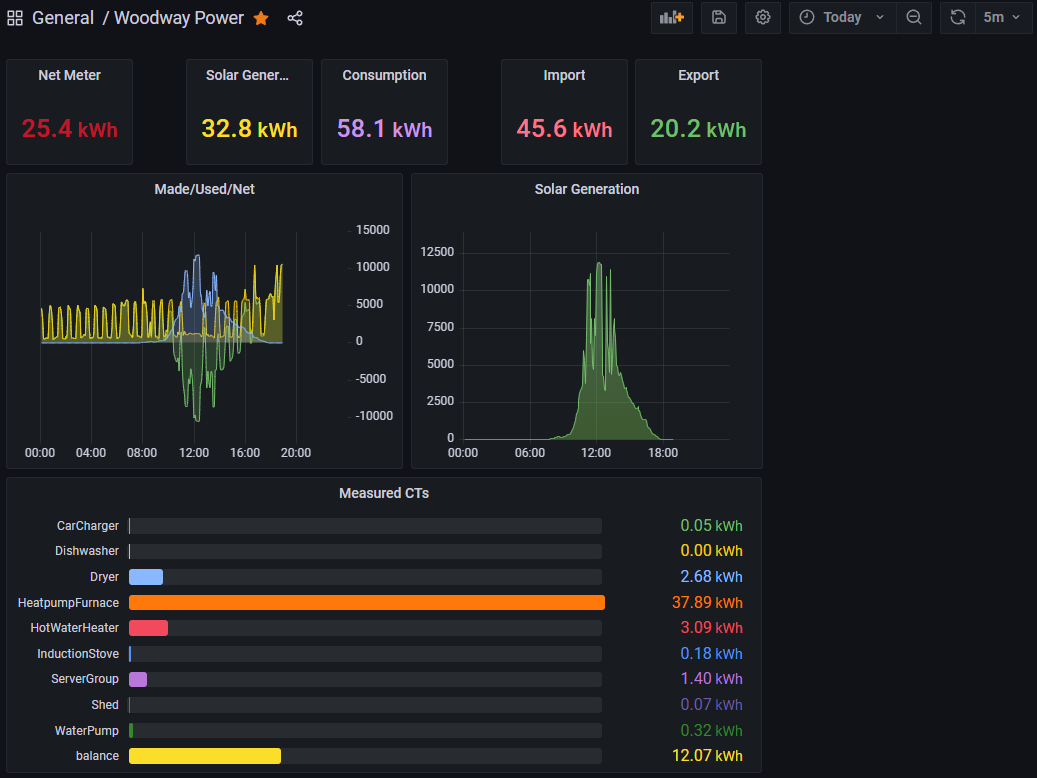
@BungledPossum are you using Influxdb v2 with the flux language? Here is my current dash with influxdb v2 through Grafana. I got some inspiration from the phisaver.com site (he has a live demo up). I’m new to the flux queries - and I’m stuck on some things. One is creating a daily (and monthly) bar graph with consumption, production, net - more or less like the one Home Assistant has in their energy panel.
Thanks for this I had a look at flux language and got a bit confused , I had tried using something like this for calculating the power costs for last 2mths
SELECT INTEGRAL(“value”,6s) *0.2932 / 1000000 FROM “total/watts” WHERE “value” >= 0 AND $timeFilter GROUP BY time(24h,-8h)
So will have a look at how you have done it and compare results
I’d really like to be able to create something to compare the current flat rate charging we are on to time of day charging to see if its worth the switch
Not sure I have things working configured correctly but also have been pre occupied on other stuff
Was doing things like
SELECT mean(“total”) * 29.21 /100 FROM “power_play”.“autogen”.“weekend_shoulder_kwh_daily” WHERE “ct”=‘1’ GROUP BY time(1d) FILL(0)
SELECT mean(“total”) * 15.3645 /100 FROM “power_play”.“autogen”.“everyday_off_peak_kwh_daily” WHERE “ct”=‘1’ GROUP BY time(1d) FILL(0)
SELECT mean(“total”) * 29.21 /100 FROM “power_play”.“autogen”.“weekday_shoulder_kwh_daily” WHERE “ct”=‘1’ GROUP BY time(1d) FILL(0)
SELECT mean(“total”) * 55.7734 /100 FROM “power_play”.“autogen”.“weekday_peak_kwh_daily” WHERE “ct”=‘1’ GROUP BY time(1d) FILL(0)
then using a total transform but not sure that is the best way, only a newbie at this stuff
the first lines allow me to extract the current month. the command now() will return somethign formated as YYYY-MM-DDTHH:MM:SSZ
so i am using substring to extract the first 8 chars from this return which amount to YYYY-MM- which i then concatenate with 01T00:00:00Z so that i get the string of the current year/month starting at the first day of that month at midnight.
next i select which database i am using and filter it. in this case, i am pulling from my database home_energy using the month value i previously calculated before and the current date/time and the start and end. i am choosing the two values returned from the IoTaWatt Mains1_W and Mains2_W which are the watts variable for my two mains
the next lines are needed to perform the calculations to add the two separate values and to multiply them by the total cost i pay per KWh. the first row makes a pivot table to combine the two values in the table so they are marched by time and creates a intermediary variable “_value”
the next lines perform the windowing and the integral to get watt-hours from the watts the IoTaWatt returns. if you see the second line “every: 30d,” this is telling grafana to display 30 days worth of information. the lines “|> integral(unit: 1h) |> map(fn: (r) => ({ r with _value: r._value / 1000.0})))” are used to calculate watt hours and then dividing by 1000 gives me kilo-watt hours
the last lines are “cleanup” lines where i am making things more presentable. right now if i was to look at all of the RAW data InfluxDB has sent, i would have the Mains1_W, mains2_W, the total watts i calculated, the integral, and many other columns of data which i no longer care about since i have used them to generate my final value. the “keep” command tells grafana which columns i want to keep, and so i drops all of the other data. the final one renames the column to what i want. in this case i rename it to describe the particular breakers are being monitored etc.
|> keep(columns: ["_value", “_time”])
|> rename(columns: {_value: “Total Energy Uage Per Day”, _time: “Date”})
then you can combine all of the different variables into one table for processing and organize then by time. you will want to use the “fill” commands to fill in any columns with a non-null value if the same columns are not in each of your different queries
now you can do IF statements with your data in the combined table named “overview” and if values are one way, do something and if they are a different value do something else
here is an example (not with if statements, but with multiple queries and combining them to perform a bunch of math
Thanks for taking the time to post your comprehensive reply, and taking the time to break things out and explain the various sections, I just realised I forgot to mention that I was using NodeRed to do the time of day and day of week splits but I’d much rather just have it all in one place
I’ll have play as time permits
no problem, feel free to IM me or discuss over email if you desire.
one thing that helps is if you open the web-interface of influxDB and choose your data/plot it, in the lower right there is a “script editor” button. this will actually generate the Flux language code needed for the query you just made. this helped a lot in my initial understanding.
then i just googled a lot about how to do xyz or how to do abc and ready a lot of the documentation on influxdb’s site as they explain the new flux language is fairly good detail.
i just the played around figuring out how to do different things etc. once you understand which commands to use, it is easy to understand the code, and now that i have been using it, it is so much better to use as it is crazy powerful if you need it to be.
Hi! I am starting with grafana and looking for information I saw your post. I am looking for something similar, but simplier, just know if it is 100% solar, combined or all from the line. I don’t know if you figured out how to do it, because the post didn’t continue, but i would like to know if you fixed it.
Also it would be really great if you could share your code, because it has almost the same structure i want to follow, but i am starting and have it as an example would be great.
Can you send me an screen shot or something of your data layout in Influx?
It should be fairly easy to do what you want.
We can make a single flux language query that pulls the data from your AC mains, and pulls data from your solar mains.
We then need to join the two different tables
After they are joined we can perform several IF statement where we determine the sources of power and have it report “all solar” / “All AC Mains” / combination
It would also then be easy to make a panel that shows what percentage is from mains and what is from solar when you are getting combined power.
Thx heaps @wallacebrf , this weekend gone I finally had time to convert my Influxdb to V2 so I could have a play with these.
I couldn’t work out how to do the time of day calculations easily in Flux so created different measurements for each tariff , populated via Nodered rules and then played with Grafana first using a transform to add the values then probably the cleaner method just using flux
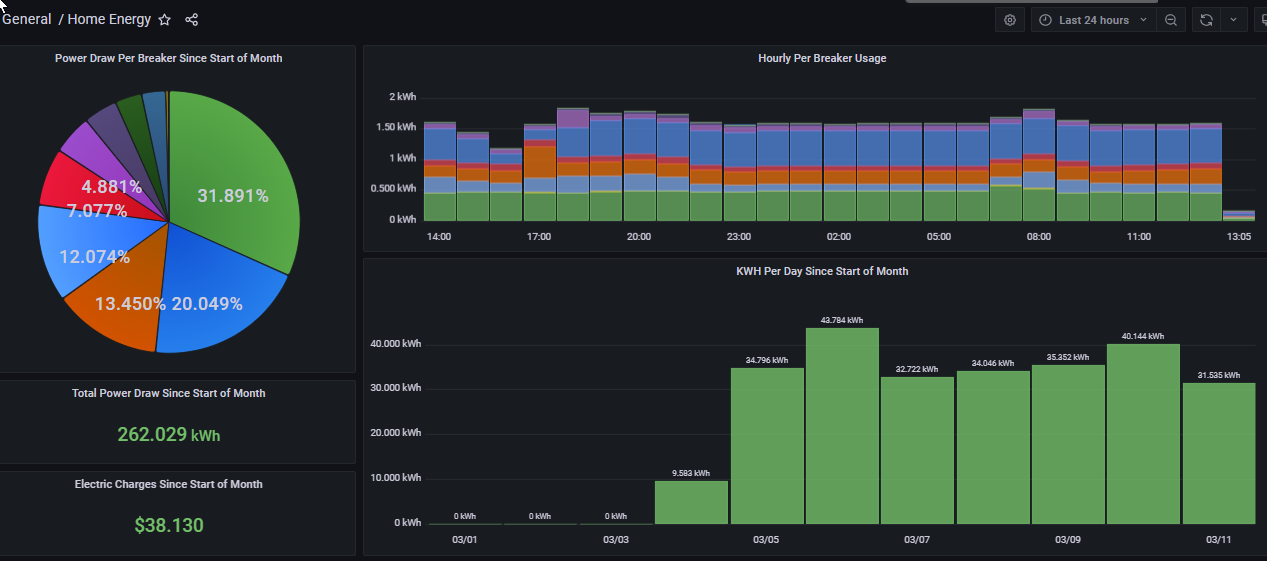
This is what came up with for graphing each day and will then work on using this as the basis for additional work
Wondering if sometime you could cast your eye over it and double check I haven’t made any stupid mistake as I certainly made plenty b4 I got to this stage, thx
import "strings"
import "date"
import "timezone"
option location = timezone.location(name: "Australia/Perth")
yesterday = date.truncate(t: -1d, unit: 1d)
from(bucket: "power_play")
|> range(start: -14d, stop: yesterday)
|> filter(fn: (r) => r._measurement == "Peak" or r._measurement == "OffPeak" or r._measurement == "SuperOffPeak")
// get the kWh
|> aggregateWindow(
every: 1d,
fn: (tables=<-, column) =>
tables
|> integral(unit: 1h)
|> map(fn: (r) => ({ r with _value: r._value / 1000.0}))
)
// apply the time of day tariff
|> map(
fn: (r) => ({r with _value:
if r._measurement == "Peak" then
r._value * 0.55
else if r._measurement == "OffPeak" then
r._value * 0.22
else
r._value * 0.08
})
)
// create a table containing data from all 3 measurements
|> pivot(rowKey: ["_time"], columnKey: ["_measurement"], valueColumn: "_value")
// if column has / need to use [] eg
//|> map(fn: (r) => ({ r with _value: r["Peak/watts"] + r["OffPeak/watts"] + r["SuperOffPeak/watts"] }))
|> map(fn: (r) => ({ r with _value: r.Peak + r.OffPeak + r.SuperOffPeak }))
|> keep(columns: ["_value", "_time"])
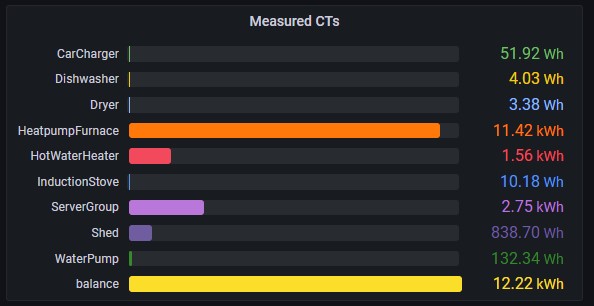
Just wanted to share my flux for my branch circuit breakers; I render as a table with the name, current power, 24h energy, and 7-day average 24h energy. I would rather render it graphically, but haven’t found the right tools for a composite presentation yet.
There are a couple little tricks in there that it took me a while to figure out.
I’ve been away from the Iotawatt forums - looks like some Influx v2/grafana experts have arrived since. I would love some help with the following -
I have Iotawatt set up to send data to my influx v2 db more or less like Bob instructs in the help file. I also set up a handful of wifi plugs that do energy monitoring via MQTT. That data is getting dumped into my influx v2 DB as well (via Home Assistant).
I have my grafana energy monitoring dashboard set up to show me kWh usage - BUT - and here’s the rub - I can’t seem to get the two different data sets together in one graph - so I have one for all the CTs from iotawatt in one graph and all my outlets in another.
my iotawatt data
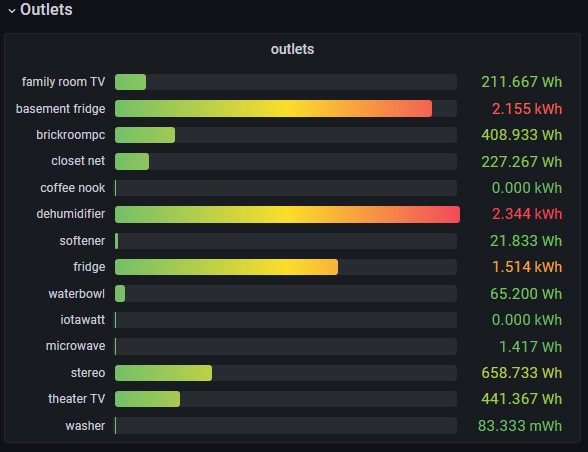
my outlet data
here are the queries -
CTs
from(bucket: “iotawatt”)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r[“_measurement”] == “CarCharger” or r[“_measurement”] == “Dishwasher” or r[“_measurement”] == “Dryer” or r[“_measurement”] == “HeatpumpFurnace” or r[“_measurement”] == “HotWaterHeater” or r[“_measurement”] == “InductionStove” or r[“_measurement”] == “ServerGroup” or r[“_measurement”] == “Shed” or r[“_measurement”] == “WaterPump” or r[“_measurement”] == “balance”)
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> integral(unit: 1000h, column: “_value”)
outlets
from(bucket: “iotawatt”)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r[“friendly_name”] == “stereo” or r[“friendly_name”] == “theater TV” or
r[“friendly_name”] == “washer” or r[“friendly_name”] == “waterbowl” or r[“friendly_name”] == “softener” or r[“friendly_name”] == “microwave” or r[“friendly_name”] == “iotawatt” or r[“friendly_name”] == “fridge” or r[“friendly_name”] == “family room TV” or r[“friendly_name”] == “dehumidifier” or r[“friendly_name”] == “coffee nook” or r[“friendly_name”] == “closet net” or r[“friendly_name”] == “brickroompc” or r[“friendly_name”] == “basement fridge”)
|> filter(fn: (r) => r[“_field”] == “value”)
|> aggregateWindow(every: v.windowPeriod, fn: mean, createEmpty: false)
|> integral(unit: 1000h)
My end game here is to have all the data in one graph and use some math to subtract all the outlet data from the ‘balance’ value in the CT graph and get a ‘true’ balance value (unmeasured power).
Sorry for the scatter brain post - but would appreciate any help here.